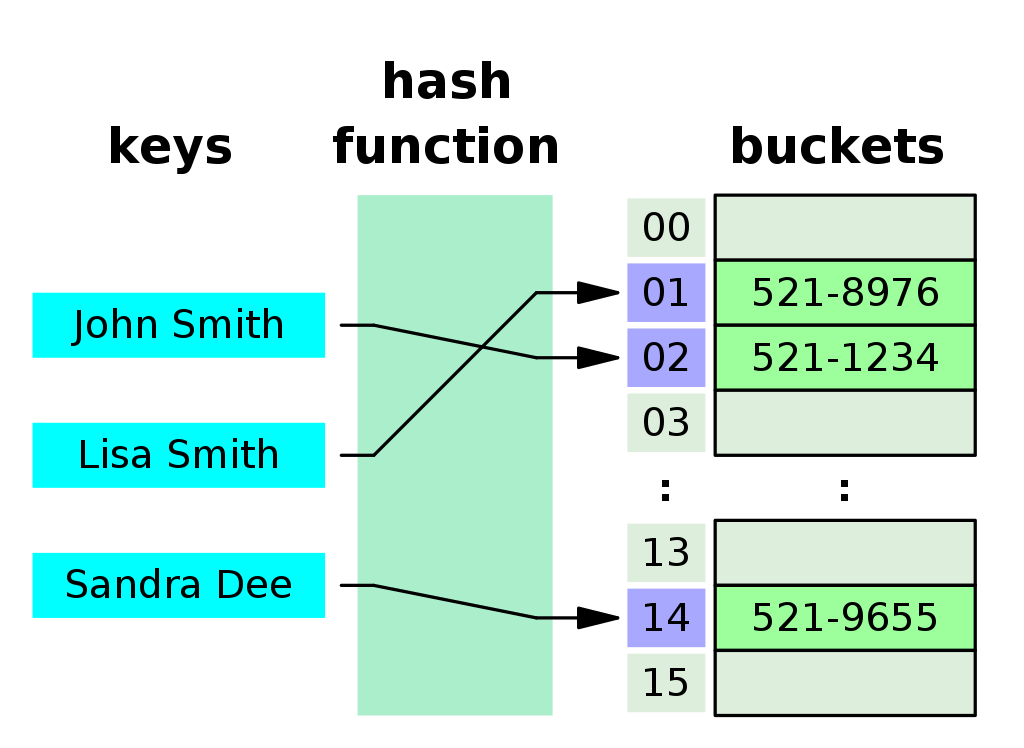
해시테이블이란?

https://en.wikipedia.org/wiki/Hash_table
HashMap이라고도 알려진 해시 테이블(HashTable)은 키(Key)를 값(Value)로 매핑하는 추상 데이터 유형입니다. 내부적으로 연관 배열(associative array)나 딕셔너리(dictionary)을 사용하여 데이터를 저장합니다.
각 키Key에 해시 함수를 사용하여 해시코드라고도 하는 인덱스(index)를 생성하고 이 index 위치에 값(Value)가 저장됩니다.
colors = {
"Red" : "#FF0000",
"Green" : "#00FF00",
"Blue" : "#0000FF",
"White" : "#FFFFFF",
"Black" : "#000000",
"Yellow" : "#FFFF00",
"Cyan" : "#00FFFF",
"Magenta": "#FF00FF",
"Gray" : "#808080",
"Orange" : "#FFA500"
}예를 들어 위의 구조에서 키는 "Gray", 값은 "#808080" 를 저장해두면 키인 Gray로 바로 값을 찾을 수 있습니다. 해시 함수를 통해 키인 "Gray"를 인덱스로 만든 후 배열의 인덱스 자리에 { “Gray” : "#808080” } 를 저장합니다.
여기서 인덱스의 범위는 해시 테이블의 크기에 의존적입니다. 예를 들어 해시테이블 크기가 100이면 해시 함수로 얻을 수 있는 인덱스의 범위는 0부터 99까지입니다.
해시 테이블에서 를 할 때 평균 시간 복잡도는 테이블에 저장된 요소의 개수와는 무관하게 O(1)입니다.
저장/삭제할 때 키Key를 기준으로 테이블에 저장/삭제할 위치를 계산하여 시행합니다. (시간복잡도 O(1)) 조회를 할 때도 위치 계산하여 O(1) 시간에 데이터를 조회합니다.
| Algorithm | Average | Worse |
| Search | O(1) | O(n) |
| Insert | O(1) | O(n) |
| Delete | O(1) | O(n) |
어떻게 사용하면 좋을까?
장점
- 평균적으로 O(1)의 시간 복잡도로 조회,삽입, 삭제를 수행할 수 있어 데이터 접근을 빠르게 합니다.
- 키를 기반으로 값을 저장하고 검색하는 구조로 데이터 관계를 보다 쉽고 명확하게 관리가 가능합니다.
- 키Key는 유일한 값으로 저장해야하므로 중복을 방지할 수 있습니다.
단점
- 해시 함수의 결과값으로 나오는 Index의 값이 중복되면 해시충돌이 일어날 수 있습니다.
- 순서대로 배열에 저장되는 것이 아니므로 순서가 필요한 로직에는 사용하기 힘듭니다.
사용 예시
- 데이터 중복 검사가 필요한 경우
- 데이터 접근을 빠르게 해야하는 경우
- 캐싱 Caching
-
- Redis에 Key-Value를 저장할 때 내부적으로 해시테이블 구조를 사용합니다.
- 이 경우 충돌하는 항목 중 하나를 삭제하여 해시 충돌을 처리하기도 합니다.
- Key-Value 구조로 데이터를 관리해야 하는 경우
해시 충돌 Hash Collision
키Key에 해시 함수를 적용했을 때 결과 값이 동일한 데이터 2개가 있다고 했을 때 어떤 것을 어떻게 저장해야 할까요? 이렇게 해시 테이블 내에 삽입하고자 하는 메모리 위치에 다른 데이터가 저장을 시도하는 경우 해시 충돌이 발생한다고 합니다.
만약 해시 함수의 결과값 범위가 무한하다면 이런 일이 일어나지 않겠지만, 해시 함수의 결과가 해시 테이블 크기 범위 이내이기 때문에 이러한 문제가 발생합니다.
이에 대한 대표적인 해결법 2개를 적용한 구현 사례를 공유하겠습니다.
Separate Chaning
- 해시 충돌이 일어나는 데이터를 연결 리스트 LinkedList 의 마지막 혹은 처음 노드로 연결해서 저장합니다.
- 해시 테이블 구현의 일반적인 방식입니다.
import java.util.*;
public class SeparateChaningHashTable<K, V> implements HashTable{
private static final float LOAD_FACTOR = 0.75f;
private LinkedList<Entry<K, V>>[] tables;
private int size;
@Override
public void put(Object key, Object value) {
if (isResizingRequired()) {
resize();
}
Entry<K, V> objectObjectEntry = new Entry<>((K)key, (V)value);
tables[hashCode(key)].add(objectObjectEntry);
numberOfItems ++;
}
직접 구현할 때 내부 자료구조를 LinkedList의 배열로 구현할 수 있습니다.
@Override
public Object get(Object key) {
if (isEmpty()) {
throw new EmptyStackException();
}
return tables[hashCode(key)].stream()
.filter(e -> e.getKey().equals(key))
.map(Entry::getValue).findAny()
.orElseThrow(() -> new NoSuchElementException("해당하는 요소가 없습니다."));
}
public int hashCode(Object key) {
return Math.abs(key.hashCode()) % tables.length;
}
}조회를 할 때는 LinkedList를 탐색하여 Key가 일치하는 데이터를 반환합니다.
Open Addressing
- 모든 항목 데이터가 배열에 저장되는 형태입니다.
- 새 항목을 삽입해야하는데 해시 충돌이 일어나면 해시된 슬롯부터 시작하여 비어있는 슬롯을 찾을 때까지 프로브 서열probe sequences 순서로 진행하면서 배열을 검사하여 먼저 찾는 빈 슬롯에 레코드를 저장합니다.
- 주로 사용하는 probe sequences 는 다음과 같습니다.
-
- 선형 탐색 Linear probing
-
- 프로브 사이 간격이 고정되어 있습니다. 보통 1입니다.
- 이차원 프로빙 Quadratic probing
-
- 원래 계산 결과값에 2차 다항식의 연속 출력을 추가하여 프로브 사이의 간격을 늘립니다.
- 더블 해싱 Double hashing
-
- 프로브 간의 간격을 보조 해시 함수로 계산합니다.
다음은 선형 탐색 방식으로 구현한 사례입니다. (기본값 1)
import java.util.*;
public class LinearProbingHashTable<K, V> implements HashTable {
private static final float LOAD_FACTOR = 0.6f;
private Entry<K,V>[] tables;
private int size;
public LinearProbingHashTable(int capacity) {
this.tables = new Entry[capacity];
this.size = 0;
}
}Entry 배열을 내부 구조로 가지고 있습니다.
@Override
public void put(Object key, Object value) {
if (isResizingRequired()) {
resize();
}
Entry<K, V> objectEntry = new Entry<>((K) key, (V) value);
int index = hashCode((K) key);
// 같은 Key가 있는지도 확인해야 합니다.. 같은 Key가 있을 경우 삽입이 불가능합니다.
while (tables[index] != null) {
index = (index + 1) % tables.length;
}
tables[index] = objectEntry;
numberOfItems++;
}
@Override
public void remove(Object key) {
int index = hashCode((K) key);
for (int i=0; i<tables.length; i++) {
if (tables[index].getKey().equals(key)) {
tables[index] = null;
numberOfItems --;
return;
}
index = (index+1)% tables.length;
}
}
@Override
public Object get(Object key) {
int index = hashCode((K) key);
for (int i=0; i<tables.length; i++) {
if (tables[index] != null && tables[index].getKey().equals(key)) {
return tables[index].getValue();
}
index = (index+1)% tables.length;
}
throw new NoSuchElementException();
}
}
이렇게 구현할 때의 가장 잊기 쉬운 점은 결국 자료구조를 순회하며 키Key가 같은 것을 찾아야 한다는 점입니다. 조회를 할때나 삭제를 할 때도 해당 위치에 있는 키Key가 일치하는지 검증하고 일치하지 않다면 index를 +1씩 하며 순회하며 탐색해주어야 합니다.
이런 경우 시간복잡도가 최악의 경우 O(n)이 됩니다.
- 코드 전체는 github에서 확인하실 수 있습니다.
참고자료
- 원티드 프리온보딩 인턴십 백엔드 2주차 자료
- Hash table wiki
- [자료구조] 해시테이블(HashTable)이란? (망나니 개발자)